The Local Stack: Run AI On Your Laptop
Running AI on Your Own Metal
- Cloud AI (Renting): The traditional model: Paying subscriptions to send data to external servers. High latency and privacy risks.
- Local AI (Owning): The new standard: Running open models on your own hardware. Zero latency, 100% private, and no monthly fees.
- Privacy & Speed: Key drivers for the shift: Enterprise security mandates and the need for real-time voice interaction.
Visual Intelligence by FactsFigs.com
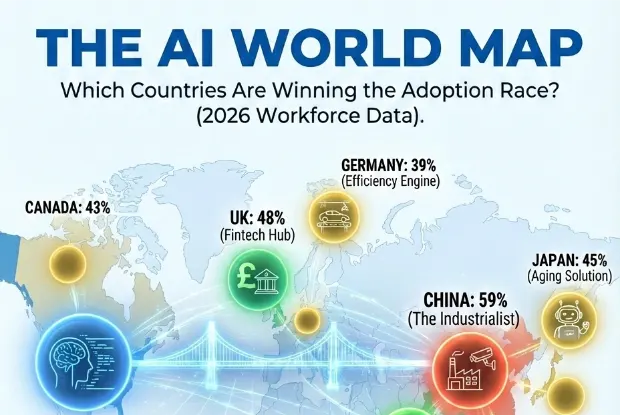
Device Shipments & Adoption Trends
Data Source: IDC Data
Overview
In 2026, the 'Cloud-Only' era of AI is effectively over. We are witnessing the 'Local Inference' revolution.
Driven by privacy fears, skyrocketing subscription costs, and the arrival of powerful 'Small Language Models' (SLMs), the power balance has shifted. Developers and power users are no longer renting intelligence; they are hosting it. With tools like Ollama and integrated NPU hardware, running a smart, private AI on a laptop is now the 'Pro' standard.
The Hardware 'Unlock'
Software was ready; now hardware has caught up. In 2024, an NPU (Neural Processing Unit) was a novelty. In 2026, it is a requirement. Over 2 billion devices now have dedicated silicon to run AI efficiently. New compression techniques mean a model that used to require a $10,000 server can now run on a standard laptop, democratizing access to high-level intelligence.
The Privacy Pivot
'If it's in the cloud, it's not yours.' Companies are tired of leaking IP. 78% of IT leaders now forbid pasting code into public chatbots, instead deploying local instances where data never leaves the building. Open-source tools that make downloading a model as easy as installing an app have exploded, proving this isn't just for hackers—it's for everyone.
Speed & Latency
When milliseconds matter, the cloud is too slow. For the new wave of 'Voice Mode' agents, network lag kills the vibe. Local models offer sub-20ms latency, enabling natural, instant interruptions that cloud APIs physically cannot match. Plus, the ultimate reliability feature is working offline—whether on a plane or in a secure facility.
Conclusion
The future of AI isn't just bigger models in the cloud; it's smarter models in your pocket.
In 2026, the mark of a sophisticated user isn't which subscription they pay for—it's which model they run.
Data Source and Attribution
Data aggregated from IDC & Gartner Device Shipment Forecasts (2026), Ollama Repository Statistics, and Deloitte's Enterprise AI Governance Report.
Disclaimer: This content analyzes technology adoption trends and projected market data.
2026-02-09
Weekly Updates
Subscribe for the FactsFigs Weekly Brief
Signals, charts, and data stories delivered every week.
More Intelligence
Other Popular Topics
Additional signals from the FactsFigs intelligence feed.